Copyright © 2020 Ashok P. Nadkarni. All rights reserved.
This document is a programmer’s guide for installing and using the tarray
extension which implements two data types — columns
and tables. It does not list or detail
every option or command implemented by the extension. See the command
reference pages accessible from the
Main Table of Contents for that information. Also see
Introduction for an overview of all the
package components and documentation.
|
|
Typed arrays can also be manipulated using Xtal, a language embeddable in Tcl that is geared towards operating on typed arrays with a more succint syntax. However, Xtal is for the most part not described in this guide. See The Xtal Language for details on its use. |
1. Motivation
Although Tcl provides for collections in the form of lists
these have limitations when dealing with large
amounts of data. These limitations, both in memory usage as well
as performance, are a result of how values are internally stored in
Tcl. The tarray extension implements collections as native data
types with parallelized operations resulting in orders of
magnitude improvement in these performance
metrics when operating on numeric data (although with only marginal
benefits for strings).
In addition to performance, the extension also offers more convenience in terms of more flexible indexing as well as a wider and more powerful set of operations on collections.
2. Installation and loading
Binary packages for some platforms are available from the Sourceforge download area. See the build instructions for other platforms.
To install the extension, extract the files from the distribution to any
directory that is included in your Tcl installation’s auto_path variable.
Once installed, the extension can be loaded with the standard Tcl package require command.
% package require tarray
→ 1.0.0The extension places its commands in the tarray namespace.
The primary commands implemented by the extension
are column and
table, each being
an ensemble of subcommands that operate on columns and
table respectively.
Other commands provide functionality like iteration and formatting that are independent of the data type.
The examples in this guide assume the commands have been imported into the calling namespace or are included in its namespace path as shown below.
% namespace path tarrayIf in addition you want to use the Xtal language, you need to load its package as well.
% package require xtal
→ 1.0.0
% namespace import xtal::xtal3. Concepts
3.1. Columns
A column is an ordered sequence of values of a single
type
that is specified when the column is created. The command
tarray::column
can be used to create and manipulate typed columns.
3.2. Tables
A table is an ordered sequence of named columns of equal
size. It can be also be viewed as an array of records where the
record fields happen to use column-wise storage. The corresponding
tarray::table command operates on
tables. Columns in a table can be referenced using either their
name or their position in the ordered sequence.
3.3. Types
All elements in a column must be of the type specified when the column is created. The following element types are available:
| Keyword | Type |
|---|---|
|
Any Tcl value |
|
A string value |
|
A boolean value |
|
Unsigned 8-bit integer |
|
Floating point value |
|
Signed 32-bit integer |
|
Unsigned 32-bit integer |
|
Signed 64-bit integer |
The primary purpose of the type is to specify what values can be stored in that column. This impacts the compactness of the internal storage (really the primary purpose of the extension) as well certain operations (like sort or search) invoked on the column.
The types any and string are similar in that they can hold any Tcl
value. Both are treated as string values for purposes of comparisons
and operators. The difference is that the former stores the value
using the Tcl internal representation while the latter stores it as a
string. The advantage of the former is that internal structure, like a
dictionary, is preserved. The advantage of the latter is significantly
more compact representation, particularly for smaller strings.
Attempts to store values in a column that are not valid for that column will result in an error being generated.
3.4. Indices
An index into a typed column or table can be specified as either an integer or
the keyword end. As in Tcl’s list commands, end specifies the index of the
last element in the tarray or the index after it, depending on the command.
Simple arithmetic adding of offsets to end is supported, for example
end-2 or end+5.
Many commands also allow multiple indices to be specified. These may take one of two forms — a range which includes all indices between a lower and an upper bound (inclusive), and an index list which may be one of the following:
-
a Tcl list of integers
-
a column of any type other than
boolean. The value of each element of the column is converted to an integer that is treated as an index. -
a column of type
boolean. Here the index of each bit in the boolean column that is set to1is treated as an index.
Note that keyword end can be used to specify a single index or as a range
bound, but cannot be used in an index list.
When indices are specified that cause a column or table to be extended, they must include all indices beyond the current column or table size in any order but without any gaps. For example,
% set I [column series 5]
→ tarray_column int {0 1 2 3 4}
% column place $I {106 105 107 104} {6 5 7 4}  → tarray_column int {0 1 2 3 104 105 106 107}
% column place $I {106 107} {6 7}
→ tarray_column int {0 1 2 3 104 105 106 107}
% column place $I {106 107} {6 7} 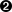 Ø tarray index 6 out of bounds.
Ø tarray index 6 out of bounds.| Ok: Indices not in order but no gaps | |
| Error: no value specified for non-existing index 5 |
The various forms for indexing are illustrated below using the
fill command which stores a value at all specified locations.
% set col [column create double {}]
→ tarray_column double {}
% set col [column fill $col 1.0 0 9]
→ tarray_column double {1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0}
% set col [column fill $col 2.0 3]  → tarray_column double {1.0 1.0 1.0 2.0 1.0 1.0 1.0 1.0 1.0 1.0}
% set col [column fill $col 2.0 end-2 end]
→ tarray_column double {1.0 1.0 1.0 2.0 1.0 1.0 1.0 1.0 1.0 1.0}
% set col [column fill $col 2.0 end-2 end]  → tarray_column double {1.0 1.0 1.0 2.0 1.0 1.0 1.0 2.0 2.0 2.0}
% set col [column fill $col 3.0 {2 7}]
→ tarray_column double {1.0 1.0 1.0 2.0 1.0 1.0 1.0 2.0 2.0 2.0}
% set col [column fill $col 3.0 {2 7}]  → tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 2.0 2.0}
% set col [column fill $col 3.0 [column create int {2 7}]]
→ tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 2.0 2.0}
% set col [column fill $col 3.0 [column create int {2 7}]]  → tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 2.0 2.0}
→ tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 2.0 2.0}| Creates a new column | |
| Indices specified as range 0 to 9 | |
| Single index 3 | |
| Range relative to end | |
| Indices specified as a list | |
Indices specified as an int column |
The last form, an integer column, is useful because some commands
return indices in that form. For example, the following will
replace all elements greater than 2.0 with 0.0.
% set col [column fill $col 0.0 [column search -all -gt $col 2.0]]
→ tarray_column double {1.0 1.0 0.0 2.0 1.0 1.0 1.0 0.0 2.0 2.0}3.5. Values and variables
Many commands that modify columns and tables come in two flavors:
-
Commands that operate on column and table values and return the modified column or table as a result (for example
fill), and -
Commands that modify a Tcl variable containing the column or table (for example
vfill).
The difference is similar to how different Tcl list commands behave, e.g.
linsert and lreplace versus lset and lappend.
The examples above used the value-oriented form of the commands
where the fill modifies a copy of the contents of the and returns
the modified copy which is then stored back into . For large typed
arrays, this is inefficient and the above would be better written
as
% set col [column create double {}]
→ tarray_column double {}
% column vfill col 1.0 0 9
→ tarray_column double {1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0}
% column vfill col 2.0 3
→ tarray_column double {1.0 1.0 1.0 2.0 1.0 1.0 1.0 1.0 1.0 1.0}
% column vfill col 3.0 {2 7}
→ tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0}
% column vfill col 3.0 [column create int {2 7}]
→ tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0}Here the vfill command is directly modifying the variable and assuming the
content is not shared, no copy needs to be made.
This guide does not necessarily illustrate both forms of every command.
4. Operating on columns
The column command is used to operate on columns.
4.1. Creating columns
The column create command creates columns
of a specified type.
% column create int
→ tarray_column int {}The above creates a column that can hold elements of the int type.
Note that the command returns a value that would normally be assigned
to a variable.
4.1.1. Creating initialized columns
A column can be initialized at creation time. Let us create some columns we will use as examples throughout this guide that tracks weather through the year.
% set months [column create string {
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
}]
→ tarray_column string {Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec}
% set temperatures [column create int {
12 14 23 28 34 30 26 25 26 22 18 15
}]
→ tarray_column int {12 14 23 28 34 30 26 25 26 22 18 15}
% set rainfall [column create double {
11.0 23.3 18.4 14.7 70.3 180.5 210.2 205.8 126.4 64.9 33.1 19.2
}]
→ tarray_column double {11.0 23.3 18.4 14.7 70.3 180.5 210.2 205.8 126.4 64.9 3...|
|
Applications should not depend on the exact string representation of a column
or table as that is liable to change. Use only the |
The above examples use a Tcl list for initialization. Alternatively, a column could also be used instead. For example,
% set first_quarter [column create any [column range $months 0 2]]
→ tarray_column any {Jan Feb Mar}Notice the initialization column type need not be the same as long as the values are compatible.
A related command is column cast which
differs in that it is less strict in terms of converting
values. For example,
% set I [column create int {255 256 257}]
→ tarray_column int {255 256 257}
% set B [column create byte $I]
Ø Value 256 does not fit in a byte.
% set B [column cast byte $I]
→ tarray_column byte {255 0 1}| Error because values do not fit in a byte | |
| No error, high order bits discarded |
Columns are resized as needed but as an optimization, preallocation may be requested.
% column create int {0 1 2 3} 1000
→ tarray_column int {0 1 2 3}This preallocates space for a thousand elements with the first four being initialized.
For the commonly useful cases of columns initialized with ones and zeroes
respectively, the column ones and
column zeroes commands.
% column ones 5
→ tarray_column int {1 1 1 1 1}
% column zeroes 3 double
→ tarray_column double {0.0 0.0 0.0}4.1.2. Creating numeric series
Columns containing equally spaced values can be created
with the column series and
column linspace commands.
% column series 10
→ tarray_column int {0 1 2 3 4 5 6 7 8 9}
% column series 5 -5 -2
→ tarray_column int {5 3 1 -1 -3}
% column series 10.0
→ tarray_column double {0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0}| 0 (default) to 10 with step 1 (default) | |
| Decreasing from 5 to -5 with step -2 | |
| Series of doubles instead of integer |
While the column series command accepts a step size, the
column linspace command accepts a interval count.
% column linspace 0 20 5
→ tarray_column double {0.0 5.0 10.0 15.0 20.0}
% column linspace 20 0 4 -type int -open true
→ tarray_column int {20 15 10 5}| Defaults to closed interval and type double | |
| Open interval of descending ints |
While column linspace generates evenly distributed values in linear fashion,
column logspace
generates evenly distributed values on a logarithmic scale.
% column logspace 2.0 3.0 4 -base 10
→ tarray_column double {100.0 215.44346900318845 464.15888336127773 1000.0}4.1.3. Creating columns with random values
The column random command creates and
initializes column with random values.
% column random boolean 16
→ tarray_column boolean {0 1 1 0 0 1 0 1 1 1 0 1 0 1 0 0}
% column random int 5 -100 100
→ tarray_column int {92 33 -11 -41 -87}| Array of 16 randomly generated booleans | |
| Array of 5 random integers in a range |
For some uses, such as testing, it is useful to be able to generate
the same sequence of random numbers on every run. The randseed
command can be used to set or reset the initial seeds used for
random number generation.
randseed 100 200 → (empty)
column random byte 10 → tarray_column byte {69 190 171 125 21 117 154 177 221 27}
column random byte 10 → tarray_column byte {199 123 28 62 181 74 95 197 253 55}
randseed 100 200 → (empty)
column random byte 10 → tarray_column byte {69 190 171 125 21 117 154 177 221 27}
randseed → (empty)
column random byte 10 → tarray_column byte {179 132 25 73 8 79 56 155 55 88} | Set the initial seeds for random number generation | |
| Set the same seeds again | |
| Notice same values generated | |
| Reset to use random initial seeds | |
| Now again non-deterministic values are generated |
4.1.4. Creating bit maps
As a convenience, boolean columns which have all bits set to 0
or to 1 can be created with column bitmap0
and column bitmap1 respectively.
% set zerobits [column bitmap0 8]
→ tarray_column boolean {0 0 0 0 0 0 0 0}
% set onebits [column bitmap1 8]
→ tarray_column boolean {1 1 1 1 1 1 1 1}Further, specific bits can be initialized to the complement.
% set bits [column bitmap0 8 {0 7}]
→ tarray_column boolean {1 0 0 0 0 0 0 1}4.2. Storing elements
A column may be modified by either storing a single value at multiple target locations or a different value at each target location. Further, the locations may be a contiguous range or an arbitrary set of indices. Depending on the command, the values may overwrite existing values or inserted.
4.2.1. Storing one value in multiple locations
The column fill and
column vfill commands store a single value
at one or more locations, either contiguous or noncontiguous.
% set I [column series 10]
→ tarray_column int {0 1 2 3 4 5 6 7 8 9}
% column fill $I 99 end
→ tarray_column int {0 1 2 3 4 5 6 7 8 99}
% column fill $I 99 1 8
→ tarray_column int {0 99 99 99 99 99 99 99 99 9}
% column fill $I 99 [column series 10 2]
→ tarray_column int {99 1 99 3 99 5 99 7 99 9}| Store a single element | |
| Store into a contiguous range | |
| Store in every other position |
4.2.2. Storing multiple values in arbitrary locations
The column place and
column vplace commands store each value
from a sequence of
values at one or more locations in a specified order
(not necessarily sequential).
% column place $I {101 102 103} [column create int {3 2 5}]
→ tarray_column int {0 1 102 101 4 103 6 7 8 9}
% column place $I [column create int {101 102 103}] {3 2 5}
→ tarray_column int {0 1 102 101 4 103 6 7 8 9}| Stores list of values at an index column | |
| Stores a column of values at an index list |
Note from the above how both values as well as indices can be specified as a Tcl list or as a column. This is true for most commands.
4.2.3. Storing multiple values in contiguous locations
The column put and
column vput commands store each value from a
sequence of values in contiguous locations starting at a
specified index.
% column vput I {60 70 80} 6
→ tarray_column int {0 1 2 3 4 5 60 70 80 9}
% column vput I $I
→ tarray_column int {0 1 2 3 4 5 60 70 80 9 0 1 2 3 4 5 60 70 80 9}| Stores values consecutively starting at index 6 | |
| Appends to itself unspecified starting index defaults to end |
4.2.4. Inserting one value in multiple locations
The column insert and
column vinsert commands
store a single repeated value a specified number of times starting
at a given index. The following command inserts the value 99
three times at index 1.
% set I [column series 5]
→ tarray_column int {0 1 2 3 4}
% column insert $I 99 1 3
→ tarray_column int {0 99 99 99 1 2 3 4}4.2.5. Inserting multiple values
The column inject and
column vinject commands insert
multiple values passed as a list or a column into contiguous
locations starting at a specified index.
% set I [column series 5]
→ tarray_column int {0 1 2 3 4}
% column inject $I {10 20 30} 2
→ tarray_column int {0 1 10 20 30 2 3 4}
% column inject $I $I 2
→ tarray_column int {0 1 0 1 2 3 4 2 3 4}| Inserts 10, 20, 30 at index 2 | |
| Inserts itself at position 2 |
4.3. Deleting elements
Elements in a column can be deleted with the
column delete and
column vdelete commands.
Succeeding elements are moved up to occupy the deleted
slots. Like the fill command, the indices of the elements to be
deleted may be specified as a single index, a range, a list of
indices or a index column.
% set I [column random int 10 -100 100]
→ tarray_column int {10 6 -29 -95 80 83 32 2 76 -39}
% column delete $I end
→ tarray_column int {10 6 -29 -95 80 83 32 2 76}
% column delete $I 3 6
→ tarray_column int {10 6 -29 2 76 -39}
% column delete $I {0 7 2}
→ tarray_column int {6 -95 80 83 32 76 -39}
% column delete $col [column search -all -lt $col 0]
→ tarray_column double {1.0 1.0 3.0 2.0 1.0 1.0 1.0 3.0 1.0 1.0}| Delete last | |
| Delete third through sixth | |
| Delete specified list | |
| Delete all negative values |
4.4. Retrieving elements
As for storing elements, there are multiple commands for
retrieving elements depending on whether multiple elements are to
be retrieved and whether they are contiguous or not.
In cases where multiple values are retrieved, they are
returned as a column by default but can be returned as a list or
dictionary (keyed by index) with the use of the -list and
-dict options.
4.4.1. Retrieving a single element
In the simplest case, the
column index command can be used to
retrieve a single element.
% column index $months 4
→ May4.4.2. Retrieving all elements
The command column values returns
all elements of a column as a Tcl list.
% column values $months
→ Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec4.4.3. Retrieving a range of elements
The command column range returns
multiple contiguously located elements.
% column range $months 0 2
→ tarray_column string {Jan Feb Mar}
% column range -list $months 0 2
→ Jan Feb Mar
% column range -dict $months 0 2
→ 0 Jan 1 Feb 2 Mar4.4.4. Retrieving an arbitrary list of elements
Multiple elements at arbitrary indices can be retrieved with the
column get command which accepts either a
index list or a index column.
% column get $months {10 7 4 7}
→ tarray_column string {Nov Aug May Aug}
% column get $months [column create int {10 7 4 7}]
→ tarray_column string {Nov Aug May Aug}
% column get -list $months [column create int {10 7 4 7}]
→ Nov Aug May AugAs seen, indices may be repeated and values are returned in order of specified indices.
Boolean index columns are treated differently in that an element is included if the corresponding bit is set in the index column.
% column get $months [column create int {1 0 1}]
→ tarray_column string {Feb Jan Feb}
% column get $months [column create boolean {1 0 1}]
→ tarray_column string {Jan Mar}Note the difference between the two results above.
4.5. Searching and filtering
4.5.1. Linear search
The column search command works similarly
to Tcl’s lsearch. It returns the indices or the values
of matching elements in a column. Like lsearch, by default
column search stops on the first match and returns the matching index.
% set col [column create int {-10 10 0 20 0 -5 5}]
→ tarray_column int {-10 10 0 20 0 -5 5}
% column search $col 0
→ 2
% column search $col 21
→ -1| Not found |
The above command returns the index of
the first element that is 0 using the default matching
operator that tests for equality. On the other hand, if the -inline
option is specified,
% column search -inline -gt $col 0
→ 10the command returns the value of the first positive element instead
of its index (using the -gt "greater than" operator).
The -all option requests all matching elements to be returned
instead of the just the first. Thus
% column search -all -gt $col 0
→ tarray_column int {1 3 6}returns an int column containging the indices of all positive elements.
This is often useful to extract corresponding elements from
another column.
% column get $months [column search -all -gt $rainfall 100]
→ tarray_column string {Jun Jul Aug Sep}When results are further used in logical operations, it is
useful to specify the -bitmap option. This causes the results to
be returned as a boolean vector where the matching indices are set
to 1. That further allows for easy logical operations.
% set not_wet [column search -bitmap -lt $rainfall 150]
→ tarray_column boolean {1 1 1 1 1 0 0 0 1 1 1 1}
% set not_dry [column search -bitmap -gt $rainfall 50]
→ tarray_column boolean {0 0 0 0 1 1 1 1 1 1 0 0}
% set moderate_months [column get $months [column && $not_wet $not_dry]]
→ tarray_column string {May Sep Oct}The -bitmap option implies -all |
|
|
Queries like this are easier to do using Xtal expressions. |
You can of course use -inline with -all to retrieve the
values instead of indices. Using the -pat pattern matching operator
as an example,
% set exes [column create string {tclsh.exe tclsh.man wish.exe}]
→ tarray_column string {tclsh.exe tclsh.man wish.exe}
% column search -all -inline -nocase -pat $exes *.exe
→ tarray_column string {tclsh.exe wish.exe}returns the values of all elements that match *.exe using case-insensitive
matching as in Tcl’s string match -nocase.
The search can be restricted to only look at specific elements using a
combination of -range and -among options. For example, find
all summer months with limited rainfall.
% column get $months [column search -all -range {4 7} -lt $rainfall 150]
→ tarray_column string {May}Similarly, using the -among option, only search the specified elements.
% column get $months [column search -all -among {4 5 6 7} -lt $rainfall 150]
→ tarray_column string {May}The option -among is particularly useful in combining
multiple searches where it can be used to constrain each search to
the results of the prior search. We will see an example of this later.
The column search command supports several matching operators
like -lt, -gt etc. See the
command reference for a full list.
|
|
The column intersect3
command offers another way to combine searches across
multiple columns as described
later.
|
4.5.2. Keyed lookup
Fore columns of type string only, the
column lookup command
provides for faster, dictionary based
retrieval. This may be beneficial for columns
used as keys in a table.
The command returns the index of matching element in the column.
% column lookup months Jun
Ø Object is not a column.
% column lookup months xxx
Ø Object is not a column.| Returns -1 if not present |
4.6. Ordering elements
Several commands offer rearranging of the elements in a column.
4.6.1. Sorting
The most common rearrangement operation is sorting. Columns are sorted
using column sort command or its
variable targeting analogue
column vsort. The commands take the
-increasing and -decreasing options to determine the sort order.
% column sort $rainfall
→ tarray_column double {11.0 14.7 18.4 19.2 23.3 33.1 64.9 70.3 126.4 180.5 205...
% column sort -decreasing $rainfall
→ tarray_column double {210.2 205.8 180.5 126.4 70.3 64.9 33.1 23.3 19.2 18.4 1...Default order is -increasing |
The -indices option will return indices instead of the sorted
values themselves. So to print months in order of increasing rainfall
% column get -list $months [column sort -indices $rainfall]
→ Jan Apr Mar Dec Feb Nov Oct May Sep Jun Aug JulThe command also supports the option -indirect where the operand
is a column whose values are indices into the column whose values
are to be sorted.
% set rain_indices [column series 12]
→ tarray_column int {0 1 2 3 4 5 6 7 8 9 10 11}
% column sort -indirect $rainfall $rain_indices
→ tarray_column int {0 3 2 11 1 10 9 4 8 5 7 6}Notice the rain_indices column is sorted in order of
the corresponding values in the rainfall column. In this
illustrative example, the indices are ordered before sorting but
that does not have to be the case.
One example of how this option is useful is illustrated later when we discuss sort stability.
4.6.2. Reversing
A simple reordering transform is reversing the order of elements.
The column reverse and
column vreverse commands can be used for
this purpose.
% column reverse $months
→ tarray_column string {Dec Nov Oct Sep Aug Jul Jun May Apr Mar Feb Jan}4.6.3. Shuffling
The column shuffle command returns the elements of a column
in random order.
% set I [column series 9]
→ tarray_column int {0 1 2 3 4 5 6 7 8}
% column shuffle $I
→ tarray_column int {8 0 4 7 2 3 6 1 5}
% column shuffle $I
→ tarray_column int {5 6 3 7 1 0 2 4 8}4.7. Arithmetic and logical operations
4.7.1. Comparing columns
The column identical and
column equal commands compare two columns in
their entirety. The difference is that the former returns 1 if
the columns have the same type in addition to elements being
equal and 0 otherwise. The latter applies a looser definition in
that the columns may be of different types.
% set I [column create int {1 2 3}]
→ tarray_column int {1 2 3}
% set S [column create string {1 2 3}]
→ tarray_column string {1 2 3}
% column identical $I $S
→ 0
% column equal $I $S
→ 14.7.2. Arithmetic operations between columns
The column math command can be used
to perform arithmetic and logical operations on columns on
a per-element basic.
The command takes multiple arguments each of which may be a column
or a scalar numeric value. For example,
% set I [column create int {10 20 30}]
→ tarray_column int {10 20 30}
% set J [column create double {10.1 19.9 30}]
→ tarray_column double {10.1 19.9 30.0}
% column math + $I $J 1000
→ tarray_column double {1020.1 1039.9 1060.0}
% column math < $I $J
→ tarray_column boolean {1 0 0}As a convenience, the above command can also be issued as
% column + $I $J 1000
→ tarray_column double {1020.1 1039.9 1060.0}
% column < $I $J
→ tarray_column boolean {1 0 0}Logical operators work similarly but are generally used with boolean columns.
% set bita [column bitmap0 5 {0 4}]
→ tarray_column boolean {1 0 0 0 1}
% set bitb [column bitmap0 5 {2}]
→ tarray_column boolean {0 0 1 0 0}
% column || $bita $bitb
→ tarray_column boolean {1 0 1 0 1}See the description of column math for all the available
operators.
4.7.3. Arithmetic operations on a column
In contrast to arithmetic commands that operate on a per-element basis, some commands operate on all elements of a single entire column.
The column sum command sums all the elements in
a column.
% column sum $J
→ 60.0The column minmax
command returns a pair containing the minimum
and maximum values in a column.
% column minmax $J
→ 10.1 30.0Note that this command is not restricted to numeric columns and will work for other types as well.
You can use the -indices option to get the indices of the minimum and
maximum values instead of the values themselves.
% column minmax -indices $J
→ 0 24.7.4. Set operations
The column intersect3
command returns a list containing the differences between two
columns, the first element being the intersection, the second
containing elements of the first that are not present in the
second, and the third containing elements from the second that are
not present in the first.
% set hot [column search -all -gt $temperatures 25]
→ tarray_column int {3 4 5 6 8}
% set wet [column search -all -gt $rainfall 150]
→ tarray_column int {5 6 7}
% lassign [column intersect3 $hot $wet] hot_and_wet hot_and_dry cool_and_wet
% column get $months $hot_and_wet
→ tarray_column string {Jun Jul}|
|
An intersect3 operation on search results is very fast, of order O(n).
The fact that an index column returned by a search is in sorted order
is internally noted by the implementation and made use of by a subsequent
intersect3.
|
4.8. Counting elements
The column size returns the number of
elements in a column.
% column size $rainfall
→ 12If you are only interested in the count for elements that match
specific criteria, you can use the
column count command instead. Thus
% column count -gt $rainfall 150
→ 3returns the number of months with heavy rainfall.
4.9. Introspecting columns
The type of a column can be retrieved with the column type command.
% column type $months
→ string
% column type $rainfall
→ double5. Operating on tables
Wherever it makes sense, commands that operate on columns have
counterparts that operate on tables. For example,
column fill and table fill, column range and table range,
and so on. Certain commands, like math operations, do not have
equivalents for obvious reasons. Conversely, tables have
additional commands like join that are not applicable to
columns.
Also like the column commands, table commands have variants that
operate on values and variables respectively, e.g.
table put and table vput. We will not always mention both
variants here; see the reference pages instead for availability
of a particular variant.
5.1. Creating tables
Tables may be created from Tcl lists or from existing columns.
5.1.1. Creating tables from list of row values
The table create command
constructs a table from a list of rows each
of which is also a list. The first argument to the command defines
the names and types of each column.
% set countries [table create {
Country string Population wide Area double
} {
{China 1350000000 9330000}
{Vatican 850 0.44}
}]
→ tarray_table {Country Population Area} {{tarray_column string {China Vatican}...5.1.2. Creating tables from columns
The table create2 command
constructs a table from a sequence of existing columns, all of
which must be the same length. Since columns are already typed,
only the column names have to be supplied.
% set monthly_temps [table create2 {
Month Temperature
} [list $months $temperatures]]
→ tarray_table {
Month Temperature
} {{tarray_column string {Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec}} {...
% set monthly_rainfall [table create2 {
Month Rainfall
} [list $months $rainfall]]
→ tarray_table {
Month Rainfall
} {{tarray_column string {Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec}} {...5.2. Operating on table columns
5.2.1. Retrieving table columns
The table column command returns a single
column from a table.
The table columns command returns a list
containing one or more columns from a table.
% table column $countries Country
→ tarray_column string {China Vatican}
% table columns $countries {Country 1}
→ {tarray_column string {China Vatican}} {tarray_column wide {1350000000 850}}
% table columns $countries
→ {tarray_column string {China Vatican}} {tarray_column wide {1350000000 850}} ...| Columns may be specified by name or index | |
| Defaults to returning all columns |
5.2.2. Extracting a subtable
The table slice command returns a new table
containing one or more columns from a table.
% table slice $countries {Country Area}
→ tarray_table {Country Area} {{tarray_column string {China Vatican}} {tarray_c...5.2.3. Subsetting columns in commands
While closely paralleling the commands that store values in columns, commands storing rows in tables have an additional consideration that is not applicable to columns. A table row consists of an ordered sequence of values from multiple columns. When reading or storing data, it is often convenient to operate only on a subset of these, and moreover to retrieve or provide the values in a different order than the column order of the table.
Many table commands accept the -columns option for this
purpose. Commands that retrieve data will only return the cells
for those specified columns and in that specific order.
5.3. Storing rows
5.3.1. Storing a single row in multiple locations
The table fill and
table vfill commands store a single row
in one or more locations. Like column fill, the destination may
be a single row, a range of rows or at specified row indices.
% table vfill countries {Russia 143967000 16.38e6} end+1
→ tarray_table {Country Population Area} {{tarray_column string {China Vatican ...Note use of end+1 notation |
5.3.2. Storing rows in arbitrary locations
The table place and table vplace
commands store one or more source rows at one or more locations in
the table in a specified order.
Assuming the Vatican City and China both experiences some population growth.
% table vplace -columns {Population} countries {
{1000}
{1370000000}
} {1 0}
→ tarray_table {Country Population Area} {{tarray_column string {China Vatican ...Notice this example makes use of the -columns option to update
only a single column. Also note the supplied indices need not be
in order.
|
|
The columns option value and the row values are placed in braces
though not really required here because they are actually lists of
single elements. You would need braces if updating multiple columns.
|
5.3.3. Storing rows in contiguous locations
The table put and table vput
commands store one or more source rows in a contiguous range of
locations in the table.
% table vput -columns {Population Country Area} countries {
{320000000 USA 9.16e6}
{ 82500000 Germany 349000}
}
→ tarray_table {Country Population Area} {{tarray_column string {China Vatican ...Note use of the -columns option as we are providing row fields in a different order |
Although the above examples supplied the rows in the form of a nested list, the command will also accept a table of the same shape as the destination.
5.3.4. Inserting one row in multiple locations
The table insert and
table vinsert commands
store a single row value a specified number of times starting at a
given index,
pushing existing rows further to the end of the table.
% table vinsert countries {Brazil 201000000 8358000} 2
→ tarray_table {Country Population Area} {{tarray_column string {China Vatican ...| Inserts at index 2, (just once because no count specified) |
5.3.5. Inserting multiple rows
The
table inject and
table vinject commands insert
multiple rows, passed as a list or a compatible table, at a
specified index in a table.
% table vinject countries {
{Ghana 28000000 227533}
{India 1320000000 2973000}
} 0
→ tarray_table {Country Population Area} {{tarray_column string {Ghana India Ch...| Insert at beginning of table |
5.4. Deleting rows
Rows in a table can be deleted with the
table delete and
table vdelete commands.
Succeeding rows are moved up to occupy the deleted
slots. The indices of the rows to be
deleted may be specified as a single index, a range, a list of
indices or a index column.
% set small_countries [column search -all -lt [table column $countries Population] \
100000]
→ tarray_column int {3}
% table vdelete countries $small_countries
→ tarray_table {Country Population Area} {{tarray_column string {Ghana India Ch...5.5. Retrieving rows
As for columns, there are multiple commands for retrieving rows
from a table and again as for columns, for multiple row retrieval
they all support the -list or -dict option return the rows as
a list or dictionary instead of the default table format.
5.5.1. Retrieving a single row
In the simplest cast, the table index
command can be used to retrieve a single element.
% table index $countries end
→ Germany 82500000 349000.05.6. Retrieving all rows
The table rows command returns all rows in a table as a list.
% table rows $countries
→ {Ghana 28000000 227533.0} {India 1320000000 2973000.0} {China 1370000000 9330...5.6.1. Retrieving a range of rows
The command table range returns
multiple contiguously located rows.
% table range $countries 0 2
→ tarray_table {Country Population Area} {{tarray_column string {Ghana India Ch...
% table range -list $countries 0 2
→ {Ghana 28000000 227533.0} {India 1320000000 2973000.0} {China 1370000000 9330...
% table range -dict $countries 0 2
→ 0 {Ghana 28000000 227533.0} 1 {India 1320000000 2973000.0} 2 {China 137000000...5.6.2. Retrieving an arbitrary list of rows
The get command retrieves rows at noncontiguous indices specified as a Tcl list or column:
% table get -columns {Country Population} $countries [column search -all -lt \
[table column $countries Area] 1000000]
→ tarray_table {Country Population} {{tarray_column string {Ghana Germany}} {ta...Note the use of the -columns option to retrieve only a subset of the
table columns.
5.6.3. Comparing table
The table identical and
table equal commands compare two tables in
their entirety. The difference is that the former returns 1 if
the tables have the same column names and the
column identical command returns true for every corresponding
pair of columns,
and 0 otherwise. The latter applies a looser definition in
that the column equal is used to compare columns and the column
names may differ.
5.7. Searching tables
To search tables, use the search on individual columns. For
example, the fragment below returns names of countries that are
populous and large in area. Note how the outer search is limited
to specific indices using the -among option.
% set pop_col [table column $countries Population]
→ tarray_column wide {28000000 1320000000 1370000000 201000000 143967000 320000...
% set area_col [table column $countries Area]
→ tarray_column double {227533.0 2973000.0 9330000.0 8358000.0 16380000.0 91600...
% table get -list -columns {Country} $countries [column search -all -among [column \
search -all -gt $pop_col 250000000] -gt $area_col 5e6]
→ China USA|
|
Note again that for more complex queries, it is more convenient to use the
Xtal extension instead of some combination
of |
5.8. Ordering rows
5.8.1. Sorting tables
Tables are sorted using the table sort
command. This is a thin wrapper around the column sort command
and thus takes many of the same options.
% print [table sort -columns {Country Population} -nocase $countries Country]
→ +-------+----------+
|Country|Population|
+-------+----------+
|Brazil | 201000000|
+-------+----------+
|China |1370000000|
+-------+----------+
|Germany| 82500000|
...Additional lines omitted...The above prints a table slice sorted based on country name.
5.8.2. Nested sorts and sort stability
When sorting tables, for display purposes for example, it is often necessary to display elements that have the same value in the sort column in the same order that they were previously displayed. Although, individual column sorts are stable, this is not enough when sorting across multiple columns. In such cases, the -indirect option to the sort command provides a solution. Using this option allows sorting where the "initial" ordering of elements is different from the actual order of elements in the column. An example will clarify this.
Consider a table that stores heights and weights.
% set tab [table create {name string height int weight int} {
{Jeff 180 80}
{John 175 80}
{Jim 170 75} }]
→ tarray_table {name height weight} {{tarray_column string {Jeff John Jim}} {ta...The user may choose to sort the table by height which boils down to the following code:
% table get -list $tab [column sort -indices [table column $tab height]]
→ {Jim 170 75} {John 175 80} {Jeff 180 80}This results in the table being displayed in the order Jim, John, Jeff.
The user may then choose to sort by weight.
% table get -list $tab [column sort -indices [table column $tab weight]]
→ {Jim 170 75} {Jeff 180 80} {John 175 80}resulting in a display in order Jim, Jeff, John. Since they
actually have the same value in the new sort column, this
interchange of positions between Jeff and John is
disconcerting to the user. Use of the -indirect option overcomes
this problem.
% set indices [column sort -indices [table column $tab height]]
→ tarray_column int {2 1 0}
% table get -list $tab $indices
→ {Jim 170 75} {John 175 80} {Jeff 180 80}Now use previous order of indices to order elements when their values in the weight column are equal
% table get -list $tab [column sort -indirect [table column $tab weight] $indices]
→ {Jim 170 75} {John 175 80} {Jeff 180 80}In this last statement, the sort is done indirectly using values from table but the positioning of elements when these values compare equal is based on the order in the original table.
5.8.3. Reversing tables
The order of rows in a table can be reversed with the
table reverse or
table vreverse commands.
% print [table reverse $countries]
→ +-------+----------+----------+
|Country|Population| Area|
+-------+----------+----------+
|Germany| 82500000| 349000.0|
+-------+----------+----------+
...Additional lines omitted...5.9. Joining tables
The table join command implements basic
database-type join functionality between tables.
% print [table join $monthly_rainfall $monthly_temps]
→ +-----+--------+--------+-----------+
|Month|Rainfall|Month_t1|Temperature|
+-----+--------+--------+-----------+
|Apr | 14.7|Apr | 28|
+-----+--------+--------+-----------+
|Aug | 205.8|Aug | 25|
...Additional lines omitted...By default, the join is done on the first column name that is
common between the tables. The -on option can be used to change
that. The result table includes all columns with duplicate columns
being renamed as shown above. The -t0cols and -t1cols options
can be used to control which columns are included from each table.
% print [table join -t1cols Temperature $monthly_rainfall $monthly_temps]
→ +-----+--------+-----------+
|Month|Rainfall|Temperature|
+-----+--------+-----------+
|Apr | 14.7| 28|
+-----+--------+-----------+
|Aug | 205.8| 25|
...Additional lines omitted...5.10. Counting rows
The table size command returns the number of
rows in a table.
% table size $countries
→ 75.11. Introspecting tables
Several commands return information about the definition of a table.
The table cnames
command returns a
list containing the names of the columns in a table.
% table cnames $countries
→ Country Population AreaThe table ctype command returns the type of a
column.
% table ctype $countries Area
→ doubleIf the full table definition is desired, it can be retrieved with
table definition.
The returned string is in a form that can be
used with table create.
% table definition $countries
→ Country string Population wide Area double6. Looping
The loop command iterates over a column or
table executing a script for every element or row.
% loop row $countries {
puts $row
}
→ Ghana 28000000 227533.0
India 1320000000 2973000.0
China 1370000000 9330000.0
...Additional lines omitted...A variation includes the element or row index as an iteration variable.
% loop rowindex row $countries {
puts "Row $rowindex: $row"
}
→ Row 0: Ghana 28000000 227533.0
Row 1: India 1320000000 2973000.0
Row 2: China 1370000000 9330000.0
...Additional lines omitted...The command can be used within a coroutine context to yield values.
proc loopy col {
yield;
tarray::loop elem $col {
yield $elem
}
}
coroutine next_month loopy $monthsWe can next retrieve each element using the iterator.
% next_month
→ Jan
% next_month
→ Feb7. Grouping operations
Several commands are targeted towards making grouping of data and summarization of columns and tables easier and more convenient.
7.1. Computing histograms
For example, suppose we want to classify monthly rainfall into
four categories — scanty, light, moderate and heavy — and find
how many months fall into each category. We can use the
column histogram command for the purpose.
% print $rainfall stdout -full 1
→ 11.0, 23.3, 18.4, 14.7, 70.3, 180.5, 210.2, 205.8, 126.4, 64.9, 33.1, 19.2
% print [column histogram -cnames {Rainfall NumMonths} $rainfall 4]
→ +------------------+---------+
| Rainfall|NumMonths|
+------------------+---------+
| 11.0| 6|
+------------------+---------+
| 60.8| 2|
+------------------+---------+
| 110.6| 1|
+------------------+---------+
|160.39999999999998| 3|
+------------------+---------+The above divies up the range of values in the column into 4 equal intervals and counts the number of values that falls in each. The result is a table of two columns, the first being the lower bound of each interval and the second being the number of values that fall into that interval.
The above looks even more crude than usual, so we can use the
-min and -max options to control the limits.
% print [column histogram -cnames {Rainfall NumMonths} -min 0 -max 240 $rainfall \
4]
→ +--------+---------+
|Rainfall|NumMonths|
+--------+---------+
| 0.0| 6|
+--------+---------+
| 60.0| 2|
+--------+---------+
| 120.0| 1|
+--------+---------+
| 180.0| 3|
+--------+---------+Note that when either option is used, any values that do not fall within those limits are ignored.
By default the command applies the counting function to each grouping as seen above. For other possibilities, refer to the command documentation.
7.2. Grouping into categories
Histograms are a special case of grouping that applies to
numerical columns where values are grouped by range.
A more general form is the column categorize
command.
Suppose we want to categorize the months by their first letters and print how many months start with each letter (why? To which I say, why not?).
proc first_letter {elem_index elem_value} {
return [string toupper [string index $elem_value 0]]
}
print [column categorize -cnames {Letter Months} -values -categorizer \
first_letter $months]
→ +------+----------------------------------+
|Letter|Months |
+------+----------------------------------+
|J |tarray_column string {Jan Jun Jul}|
+------+----------------------------------+
|F |tarray_column string {Feb} |
+------+----------------------------------+
|M |tarray_column string {Mar May} |
+------+----------------------------------+
|A |tarray_column string {Apr Aug} |
+------+----------------------------------+
|S |tarray_column string {Sep} |
+------+----------------------------------+
|O |tarray_column string {Oct} |
+------+----------------------------------+
|N |tarray_column string {Nov} |
+------+----------------------------------+
|D |tarray_column string {Dec} |
+------+----------------------------------+Notice that the associated value for each category is itself a
column containing the actual values. The column summarize
command discussed in the next section provides a mean to further
process this by aggregating the nested columns elements.
|
|
Although we do not show an example here, by default the
categorize command returns the indices of the elements
belonging to that category, not their values. Hence the use of the
-values option.
|
Although slower than the histogram command, the categorize command
is more general and is useful for numerical values as well, for example if
we do not want the intervals to be equal. The code fragment below
classifies rainfall in a month as scant, moderate or heavy
in a similar fashion to our earlier example except that here
the intervals are not the same size.
proc rain_class {elem_index elem_value} {
if {$elem_value < 50} {
return scant
} elseif {$elem_value < 200} {
return moderate
} else {
return heavy
}
}
print [column categorize -cnames {Category Rainfall} -categorizer rain_class \
-values $rainfall]
→ +--------+----------------------------------------------------+
|Category|Rainfall |
+--------+----------------------------------------------------+
|scant |tarray_column double {11.0 23.3 18.4 14.7 33.1 19.2}|
+--------+----------------------------------------------------+
|moderate|tarray_column double {70.3 180.5 126.4 64.9} |
+--------+----------------------------------------------------+
|heavy |tarray_column double {210.2 205.8} |
+--------+----------------------------------------------------+7.3. Summarizing categorized data
Placing values into categories is only the first step. The next step
is to process the categorized data to provide some useful information.
The column summarize command is intended
for this purpose. It takes a column of the form returned by the
categorize (or histogram with appropriate options) and
aggregates the values associated with each category with some
prescribed function.
For example, to print the number of months in each rainfall category as we did in our previous example, we could have also taken this route.
set rain_by_category [column categorize -cnames {Category Rainfall} -categorizer \
rain_class -values $rainfall]
print [table summarize -cname NumMonths $rain_by_category]
→ +--------+---------+
|Category|NumMonths|
+--------+---------+
|scant | 6|
+--------+---------+
|moderate| 4|
+--------+---------+
|heavy | 2|
+--------+---------+| Collect values in each category |
The above takes an additional step compared to what we saw earlier, but once we have categorized the original data, it makes it easier to summarize using a different, even custom, aggregation function. For example, to print the average,
proc average {cat_index cat_col} {
set n [column size $cat_col]
if {$n == 0} {return "-"}
return [expr {[column sum $cat_col] / $n}]
}
print [table summarize -summarizer average -cname AveRainfall $rain_by_category]
→ +--------+-----------+
|Category|AveRainfall|
+--------+-----------+
|scant |19.95 |
+--------+-----------+
|moderate|110.525 |
+--------+-----------+
|heavy |208.0 |
+--------+-----------+8. Formatting output
The Tcl puts command is not always suitable for printing
the values for several reasons. The output
is not formatted and hence difficult to read as you have probably
noted from some of the previous output. The
print command
provides an alternative that outputs a more readable format.
% print [table column $countries Population] -head 1 -tail 1
→ 28000000, ..., 82500000
% print $countries
→ +-------+----------+----------+
|Country|Population| Area|
+-------+----------+----------+
|Ghana | 28000000| 227533.0|
+-------+----------+----------+
|India |1320000000| 2973000.0|
+-------+----------+----------+
|China |1370000000| 9330000.0|
+-------+----------+----------+
|Brazil | 201000000| 8358000.0|
+-------+----------+----------+
|Russia | 143967000|16380000.0|
+-------+----------+----------+
|USA | 320000000| 9160000.0|
+-------+----------+----------+
|Germany| 82500000| 349000.0|
+-------+----------+----------+By default the command only prints the first few and last few elements although this can be controlled by various options.
The prettify command is similar except that it
returns the formatted string instead of printing it to a channel.
Another command that helps with formatting data is the
column width command. This returns the
maximum number of characters required to display elements
of the column in a given format.
% set col [column create int {-1000 10 100}]
→ tarray_column int {-1000 10 100}
% column width $col
→ 5
% column width $col %x
→ 8
% column width $col "The number is %d."
→ 20| Use default format string | |
| Specify the format string | |
| A generalized format string |
9. Export and import
9.1. Importing from a database
The result set from a TDBC database query can be imported into tarray tables
with the table dbimport resultset command.
Naturally, the number of table columns and types have to match those of
the result set.
% package require tdbc::sqlite3
→ 1.1.1
% tdbc::sqlite3::connection create db ../data/northwind_small.sqlite
→ ::db
% set stmt [db prepare {
SELECT CompanyName,OrderCount
FROM Customer
INNER JOIN (SELECT `Order`.CustomerId AS CID, COUNT(*) AS OrderCount
FROM `Order`
GROUP BY `Order`.CustomerId)
WHERE Customer.id=CID
}]
→ ::oo::Obj60::Stmt::1
% set rs [$stmt execute]
→ ::oo::Obj61::ResultSet::1
% set order_table [table create {Company any Orders int}]
→ tarray_table {Company Orders} {{tarray_column any {}} {tarray_column int {}}}
% table dbimport resultset $rs order_table
% table print $order_table
→ +----------------------------------+------+
|Company |Orders|
+----------------------------------+------+
|Alfreds Futterkiste | 6|
+----------------------------------+------+
|Ana Trujillo Emparedados y helados| 4|
+----------------------------------+------+
...Additional lines omitted...Alternatively, an entire table, or a subset of its columns, can be read
with the table dbimport table command. In this case,
a new tarray table is returned with the column names matching the column
names of the database table as returned by TDBC.
% table print [table dbimport table db Customer {CompanyName ContactName \
ContactTitle}]
→ +----------------------------------+-----------------------+-----------------...
|CompanyName |ContactName |ContactTitle ...
+----------------------------------+-----------------------+-----------------...
|Alfreds Futterkiste |Maria Anders |Sales Representat...
+----------------------------------+-----------------------+-----------------...
|Ana Trujillo Emparedados y helados|Ana Trujillo |Owner ...
+----------------------------------+-----------------------+-----------------...
...Additional lines omitted...9.2. CSV export and import
Tables can be exported to, and imported from, CSV format with
table csvexport and
table csvimport respectively.
% table print [table csvimport -sniff ../data/college.csv]
→ +------------------------------+-------+-----+------+------+---------+-------...
|Col_1 |Private| Apps|Accept|Enroll|Top10perc|Top25pe...
+------------------------------+-------+-----+------+------+---------+-------...
|Abilene Christian University |Yes | 1660| 1232| 721| 23| ...
+------------------------------+-------+-----+------+------+---------+-------...
...Additional lines omitted...The commands support a number of options for distinguishing CSV dialects. A related widget, described later, implements a configuration wizard for dialects.
10. Tk widgets
The tarray_ui package provides several widgets for
displaying and plotting column and table data.
10.1. Displaying tables
The tarray::ui::tableview widget makes it simple to display data in tables. For example, the snippet below will show the result of the database query we did earlier in with sorting and filtering capability.
package require tarray_ui
toplevel .customers
tarray::ui::tableview .customers.orders $order_table -showfilter true
pack .customers.orders -fill both -expand yesThe corresponding display table looks like
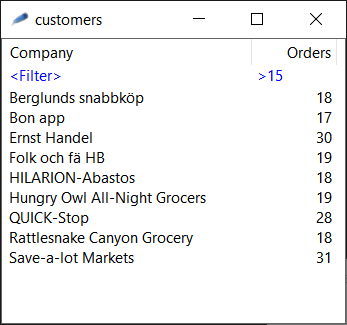
The widget supports many capabilities such as sorting, display highlighting based on cell content, filtering and automatic scrollbars. Another example is shown below.
10.2. Displaying graphs
An alternate means of displaying table data that is numeric is through graphs. The ::tarray::ui::rbcchart widget wraps the RBC Tk extension to simplify the graphing of table data. An example is shown below.
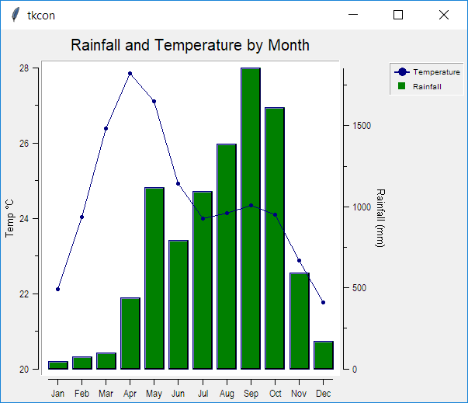
See the reference for the corresponding code.
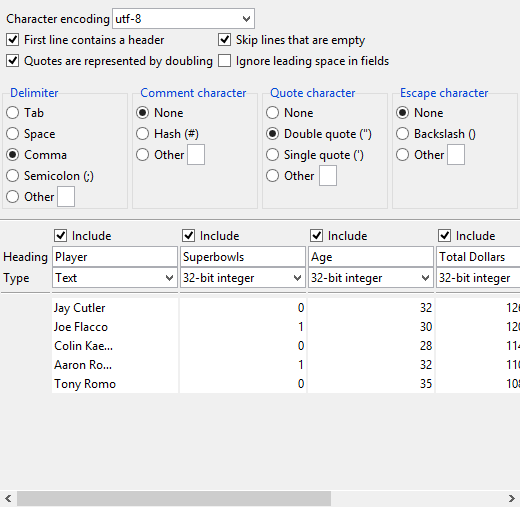
10.3. CSV import configuration wizard
The ::tarray::ui::csvreader widget is an interactive wizard for importing data from CSV files into tables. The widget, pictured below, can be used to interactively select the various CSV formatting conventions for reading CSV files into tables.
11. Random numbers
We saw earlier the construction of columns containing randomly generated
values. Random numbers can also be directly generated using the
tarray::rng command. This returns a command object which can then
be invoked to generate values of the appropriate type.
% rng create myrng int
→ ::myrng
% myrng get
→ -806637122
% myrng get 5
→ 2004083331 569346569 -265224726 -264970162 -1034404393
% myrng destroy | Create a random number generator for integers | |
| Gets a random integer | |
| Get 5 random integers | |
| Release resources when no longer needed |
The rng new command behaves similarly except a command name need
not be specified. Moreover, both forms take an optional argument
to generate random numbers within a specified range.
% set r [rng new double 1.0 2.0]
→ ::tarray::rng1
% $r get 3
→ 1.4543240893412457 1.2454754057437551 1.632656298387691
% $r destroy| Generate real numbers between 1.0 and 2.0 |
For testing purposes, the generator can be initialized with a specific seed to reproduce the same sequence everytime.
% rng create myrng byte 10 20
→ ::myrng
% myrng seed 1000 2000
% myrng get 5
→ 14 11 17 19 18
% myrng get 5
→ 19 13 15 17 17
% myrng seed 1000 2000
% myrng get 5
→ 14 11 17 19 18
% myrng get 5
→ 19 13 15 17 17
% myrng destroy| Any 64-bit seed values | |
| Reset seeds |
As seen, the same sequence is reproduced by initializing the seed with specific values.
12. Usage Hints
When specifying indices to commands, Tcl lists of integers and columns of
type int are usually interchangeable. Similarly, when passing multiple
values to a command, either a Tcl list or a column of the appropriate type
can be used. Note there is an ambiguity in the specific case where the
target of the command is a column of type any and the passed operand is a
string of the form tarray any {…}
where the operand can be interpreted either as a column or a Tcl list with
three elements tarray, any and the {…}. In this case the operand
gets interpreted as a column.
Given that the tarray extension is meant for dealing with
large amounts of data, it is useful to keep in mind Tcl’s
object reference counting and copy-on-write
implementation. Modifying a typed array that is shared will
result in a copy being made, which can be expensive if the
array is large. So, to modify a variable that contains a
typed array, the command
% column vput I [list 100 200]
→ tarray_column int {10 20 30 100 200}is far more efficient than
% set I [column put $I [list 100 200]]
→ tarray_column int {10 20 30 100 200 100 200}assuming the value in is not itself shared. This is similar to use of Tcl’s
lset command to modify lists.
As arrays get large tarray prioritizes memory usage over efficiency. As
arrays grow, the additional extra memory is conservatively allocated
(unlike Tcl which aggressively allocates extra memory).
If the size of a typed array
can be estimated in advance, for example, reading records from a database,
the memory can be preallocated.
% column create int {} 1000000
→ tarray_column int {}preallocates space for a million elements.
Typed arrays are by design implemented as consecutive elements in contiguous memory. Certain operations, such as insertion and deletion, will not be efficient when arrays get very large. For applications where such operations are common, other structures should be built on top using typed arrays as the lower level building blocks. Such higher level structures can be scripted and customized for specific usage patterns easily as they can be implemented at the script level using the low level typed array operations for efficiency. Whether this is required or not should be determined based on application benchmarks.
Both lists and columns have some differences in terms of functionality. Columns do not have the -stride option but the same functionality can be implemented through tables. List indexing offers nesting while although columns can be nested, the nested columns have to be explicitly accessed. On the other hand, columns offer some additional functions such as intersect3 and indexing operations (eg. extraction or storing of multiple elements through index lists).
anyColumns of type any are stored as Tcl_Obj objects internally
and thus are very similar to Tcl lists. Any advantage of an any
typed array over using a simple Tcl list in terms of the memory
footprint comes only from conservative memory overallocation, not
from reduced memory size of individual elements. It is therefore
not as big a benefit as for other types. Thus columns of type
any are mostly beneficial when used in conjunction with other
column types, for example in a table.
Note that columns of type string are more efficient than type
any for storing small strings.
The type any can be any Tcl value, including typed
arrays. Typed arrays can therefore be nested (tables are currently
implemented as nested columns). However, unlike some of the Tcl
list commands, tarray does not have commands that implicitly
support nesting. Nested typed arrays have to be explicitly
accessed as such.
column index [column index $outer_column 4] 0The package internally keeps track of the sorting state of a column. A column is internally marked after certain operations where the result is known to be sorted. An obvious example is the column sort command. A less obvious case is an index column returned from certain search operations. Several commands make use of this for more efficient operation. For example, the column intersect3 command is much faster when columns are known to be sorted. Thus finding the intersection of two index columns resulting from searches is an O(n) operation.